 WuT1ao
WuT1aoJAVASCRIPT
JavaScript 设计模式
JavaScript 中常用的设计模式(Design Patterns)可以帮助写出更清晰、可维护、可扩展的代码。
创建型模式(Creational Patterns)
用来创建对象的模式,关注“怎么创建对象”。
工厂模式(Factory)
通过一个函数来根据条件创建不同类型的对象。
function createUser(role) {
if (role === "admin") {
return { role: "admin", permissions: ["all"] };
} else {
return { role: "user", permissions: ["read"] };
}
}构造函数模式(Constructor)
使用 new 关键词创建对象。
function Person(name) {
this.name = name;
}
const p = new Person("Alice");原型模式(Prototype)
复用对象的属性或方法。
const person = {
greet() {
console.log("Hi!");
}
};
const student = Object.create(person);
student.greet(); // Hi!单例模式(Singleton)
确保一个类只有一个实例。
const Singleton = (function () {
let instance;
function createInstance() {
return { name: "I am the only one" };
}
return {
getInstance() {
if (!instance) {
instance = createInstance();
}
return instance;
}
};
})();结构型模式(Structural Patterns)
关注“如何组合对象和类”。
装饰器模式(Decorator)
动态添加功能,而不改变原对象。
function car() {
return { drive() { console.log("Driving"); } };
}
function withTurbo(car) {
car.turbo = true;
const baseDrive = car.drive;
car.drive = function () {
baseDrive();
console.log("With turbo!");
};
return car;
}
const myCar = withTurbo(car());
myCar.drive(); // Driving \n With turbo!适配器模式(Adapter)
把一个接口转成另一个适配目标接口。
function oldAPI() {
return "old";
}
function adapter() {
const result = oldAPI();
return { value: result };
}代理模式(Proxy)
通过代理控制对象访问。
const user = {
name: "Tom",
age: 25
};
const proxyUser = new Proxy(user, {
get(target, key) {
console.log("访问了属性:" + key);
return target[key];
}
});行为型模式(Behavioral Patterns)
关注“对象之间的通信、职责分配”。
观察者模式(Observer)
一个对象状态改变,自动通知所有订阅者。
class Observable {
constructor() {
this.subs = [];
}
subscribe(fn) {
this.subs.push(fn);
}
notify(data) {
this.subs.forEach(fn => fn(data));
}
}
const ob = new Observable();
ob.subscribe(data => console.log("接收到:", data));
ob.notify("Hello");策略模式(Strategy)
定义一组算法,使它们可以互换使用。
const strategies = {
add(a, b) { return a + b; },
sub(a, b) { return a - b; }
};
function calc(type, a, b) {
return strategies[type](a, b);
}命令模式(Command)
将操作封装成命令对象。
function Command(execute) {
this.execute = execute;
}
const turnOn = new Command(() => console.log("Light on"));
turnOn.execute();中介者模式(Mediator)
通过一个中介统一协调多个对象之间的通信。
class ChatRoom {
static showMessage(user, message) {
console.log(`${user.name}:${message}`);
}
}
class User {
constructor(name) {
this.name = name;
}
send(message) {
ChatRoom.showMessage(this, message);
}
}
const u = new User("张三");
u.send("你好!");总结
类型 | 模式 创建型 | 工厂、构造函数、单例、原型、抽象工厂 结构型 | 装饰器、适配器、代理、桥接、组合 行为型 | 观察者、策略、命令、中介者、状态
深拷贝实现
function deepClone(obj) {
if (obj === null || typeof obj !== 'object') {
return obj
}
if (Array.isArray(obj)) {
const arr = []
for (let i = 0; i < obj.length; i++) {
arr[i] = deepClone(arr[i])
}
return arr
}
const newObj = {}
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
newObj[key] = deepClone(obj[key])
}
}
return newObj
}if (obj.hasOwnProperty(key)) 的作用是判断属性 key 是否是对象 obj 自身拥有的属性,而不是继承自原型链的属性。这是因为 for...in 循环会枚举对象的所有可枚举属性,包括继承自原型链的属性。
在进行深拷贝时,我们通常只关心对象自身的属性,而不包括继承的属性。因此,使用 hasOwnProperty 来过滤掉继承的属性,确保只复制对象自身的属性。
sort 数组排序记法
// 升序 从小到大
arr.sort((a, b) => a - b)
// 降序 从大到小
arr.sort((a, b) => b - a)在 JavaScript 的 sort 函数中,比较函数的返回值决定了元素的排列顺序。比较函数入参为 (a, b) 时:
- 如果比较函数返回负数,a 就会在 b 之前。
- 如果比较函数返回零,a 和 b 的相对位置保持不变。
- 如果比较函数返回正数,b 就会在 a 之前。
所以就 arr.sort((a, b) => a - b) 而言如果 a 小于 b,那么 a - b 会得到一个负数,所以 a 将排在 b 之前,这样就实现了从小到大的升序排序。因为比较函数是 a - b,所以返回的是元素之间的差值,这决定了它们的排列顺序。
slice 和 splice 区别
slice 方法
slice方法用于创建一个新数组,该数组是原始数组的浅拷贝。- 它接受两个参数,即切片的开始索引和结束索引(不包括结束索引的元素)。
- 不会修改原始数组,而是返回一个包含选定元素的新数组。
- 如果不提供参数,
slice将复制整个数组。
const originalArray = [1, 2, 3, 4, 5];
const slicedArray = originalArray.slice(1, 4);
console.log(slicedArray); // 输出 [2, 3, 4]
console.log(originalArray); // 输出 [1, 2, 3, 4, 5](原数组不变)splice 方法
splice方法用于更改原始数组,可以删除、替换或添加新元素。- 它接受至少两个参数,第一个参数是开始操作的索引,第二个参数是删除的元素数量。
- 除了删除元素外,
splice还可以接受额外的参数,用于在指定位置插入新元素。
const originalArray = [1, 2, 3, 4, 5];
const removedElements = originalArray.splice(1, 3, 6, 7);
console.log(removedElements); // 输出 [2, 3, 4](删除的元素)
console.log(originalArray); // 输出 [1, 6, 7, 5](原数组被修改)总结
slice创建一个新数组,不修改原数组。splice修改原数组,可以删除、替换或插入元素。
substring 和 substr 方法差异
substring 和 substr 是 JavaScript 字符串对象的两个方法,它们用于从字符串中提取子字符串。虽然它们的功能类似,但有一些关键的区别:
参数的不同
substring(startIndex, endIndex):接受两个参数,分别是开始索引和结束索引(不包括结束索引处的字符)。如果省略结束索引,则子字符串包括原始字符串中开始索引到字符串末尾的所有字符。substr(startIndex, length):接受两个参数,分别是开始索引和要提取的字符个数。如果省略第二个参数,则子字符串包括开始索引到字符串末尾的所有字符。
对负数参数的处理
substring不接受负数参数。如果传入的参数为负数,它会被当作0处理。substr允许使用负数的第一个参数,表示从字符串末尾开始的位置。例如,substr(-2)表示从倒数第二个字符开始提取。
const str = "Hello, World!";
// 使用 substring
console.log(str.substring(7, 12)); // 输出 "World"
console.log(str.substring(7)); // 输出 "World!"
// 使用 substr
console.log(str.substr(7, 5)); // 输出 "World"
console.log(str.substr(7)); // 输出 "World!"
// 负数参数
console.log(str.substr(-6)); // 输出 "World!"总的来说,substring 更灵活,因为它接受两个索引参数,而 substr 则通过一个起始索引和一个长度参数来指定子字符串。选择使用哪个方法通常取决于具体的需求。
千分位格式化数字
function formatNumber(num) {
return num.toString().replace(/(\d)(?=(\d{3})+$)/g, "$1,")
}获取当前格式化时间
function getCurrentDate() {
const today = new Date()
const year = today.getFullYear() // 获取年份
const month = String(today.getMonth() + 1).padStart(2, '0') // 获取月份(+1是因为月份从0开始,padStart用于补零)
const day = String(today.getDate()).padStart(2, '0') // 获取日期(padStart用于补零)
// 格式化成YYYY-MM-DD
const formattedDate = `${year}-${month}-${day}`
return formattedDate
}flatMap 方法用法与示例
在 JavaScript 中,flatMap 是一个数组方法,用于对数组中的每个元素执行一个函数,并将结果组合成一个新的扁平化数组。它首先使用提供的函数映射每个元素,然后将映射后的结果按照顺序连接成一个新的数组。
flatMap 方法的语法如下:
array.flatMap(callback(currentValue[, index[, array]])[, thisArg])callback:一个函数,用来对数组的每个元素执行操作,接受三个参数:currentValue:当前正在处理的数组元素。index(可选):当前元素的索引。array(可选):调用flatMap方法的数组。
thisArg(可选):在执行回调函数时使用的上下文对象。
下面是一个使用 flatMap 方法的示例:
// 假设有一个数组包含多个人的技能列表
const people = [
{ name: 'Alice', skills: ['JavaScript', 'HTML'] },
{ name: 'Bob', skills: ['Python', 'CSS'] },
{ name: 'Charlie', skills: ['Java', 'React'] }
];
// 使用 flatMap 提取所有技能并扁平化成一个数组
const allSkills = people.flatMap(person => person.skills);
console.log(allSkills);
// 输出: ['JavaScript', 'HTML', 'Python', 'CSS', 'Java', 'React']在上面的示例中,flatMap 方法将每个人的技能列表提取出来,然后将所有技能连接成一个新的扁平化数组 allSkills。
需要注意的是,flatMap 会自动忽略映射后的结果中的空项(undefined、null等),并且它只会扁平化一层,即如果映射的结果本身是数组,它不会再递归地继续扁平化。
任意元素滚动到页面顶部
可以通过 el.scrollIntoView({ behavior: 'smooth' }) 方法直接把元素滚动到可视区域,但这个方法有一个问题就是,当页面顶部的导航条是 fixed 定位时,使用 scrollIntoView 方法滚动到页面顶部时,会被导航条遮挡,所以我们需要自己实现一个滚动到页面顶部的方法。
首先我们要获取元素距离文档顶部的距离 offsetTop,然后通过 window.scrollTo 方法来滚动页面。
offsetTop:元素距离文档顶部的距离而不是距离窗口顶部的距离,这一点很重要!window.scrollTo:滚动到指定位置,当传参为对象时,可以设置滚动的行为,behavior为smooth时,滚动的行为为平滑滚动。- 传参数为对象时,
top页面要向上滚动的距离,behavior为滚动的行为,behavior为smooth时,滚动的行为为平滑滚动。
- 传参数为对象时,
const scrollTo = (id: string) => {
const el = document.getElementById(id)
if (el) {
const height = el.offsetTop
const navHeight = document.querySelector('.nav')?.clientHeight || 0
document.documentElement.scrollTo({
top: height - navHeight,
behavior: 'smooth',
})
//
}
}接口返回文件流处理
当导入文件上传给后台时,遇到一种需求,导入成功时接口返回成功,失败时返回失败的文件流,注意这里的成功和失败都是同一个接口。
导入接口
export function upload(data) {
return request({
url: `your-url`,
method: 'post',
data,
responseType: 'blob'
})
}这里我们把 responseType 设置成了 blob 类型,在接收数据的时候解析就可以了。
解析数据
customLoad(file) {
const form = new FormData()
form.append('file', file)
upload(form).then(res => {
const resData = res.data
const fileReader = new FileReader()
fileReader.onloadend = () => {
try {
const _data = JSON.parse(fileReader.result)
if (_data.code !== '90001') return this.$message.error(_data.msg)
this.$message.success('导入成功!')
} catch (err) {
// 下载文件
Export(res, '导入失败.xlsx')
}
}
fileReader.readAsText(resData)
this.importDialog.customLoading = false
this.importDialogVisible.visible = false
})
}JS 上传下载
上传导入文件
用 axios 封装导入上传时,需要传递额外的请求头:
export function importFile(data) {
return request({
headers: {
'Content-Type': 'multipart/form-data'
},
url: 'you-import-file-url',
method: 'post',
data: data
})
}然后再调用导入文件的时候:
let formData = new FormData()
let file = this.file
formData.append('file',file)
importFile(file)下载文件
当后台返回的是文件流时封装的 axios 请求需要添加 responseType:
export function exportFile(data) {
return request({
url: 'your-export-file-url',
method: 'post',
data: data,
responseType: 'blob'
})
}然后请求接口如下:
exportFile(data).then(res => {
Export(res, '下载文件名称')
})Export 内容如下:
export function Export(res, filename, type = 'xlsx') {
const blob = new Blob([res])
const fileName = `${filename}.${type}`
const elink = document.createElement('a')
elink.download = fileName
elink.style.display = 'none'
elink.href = URL.createObjectURL(blob)
document.body.appendChild(elink)
elink.click()
URL.revokeObjectURL(elink.href) // 释放URL 对象
document.body.removeChild(elink)
}js 构造函数 原型 实例 原型链 继承
JS 原型、原型链简单理解
Constructor 构造函数
通过 new 函数名 来实例化的的函数叫构造函数, 构造函数定义时首字母大写
如:
function Person() {}prototype 原型
原型就是一个 对象, 实例 继承 原型的属性. 在原型上定义的属性, 通过 继承, 实例也拥有了这个属性. 继承 这个行为是在 new 操作符内部实现的.
原型与构造函数的关系就是: 构造函数内部有一个名为 prototype 的属性, 通过这个属性就可以访问到原型.
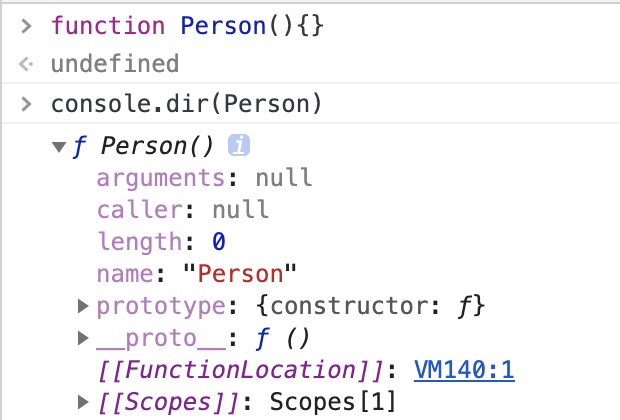
上图所示, Person 就是构造函数, Person.prototype 就是原型
instance 实例
有了构造函数就可以通过 new 操作符创建实例, 并且可以在构造函数的原型上面创建可以 继承 的属性.
例: 若要通过 Person 构造函数创建一个实例 person, 通过 new 操作符就可以实现, 可以通过 instanceof 检验 他们间的关系:
function Person() {}
var person = new Person();
// 检验 person 是否是 Person 的实例
console.log(person instanceof Person); // true在原型上定义的一个属性, 也会被实例继承这个属性:
function Person() {}
Person.prototype.age = 12;
var person = new Person();
console.log(person.age); // 12proto 隐式原型
实例可以通过 proto 访问到原型:
function Person() {}
Person.prototype.age = 12;
var person = new Person();
console.log(person.__proto__ === Person.prototype); // trueconstructor 构造函数
构造函数可以通过 ptototype 访问原型, 原型可以通过 constructor 访问构造函数
function Person() {}
Person.prototype.age = 12;
var person = new Person();
console.log(Person.prototype.constructor === Person); // true注意
这里提到的 constructor 是 原型上的一个属性, Constructor 指的才是真正的构造函数
构造函数(Constructor) 实例(Instance) 原型(prototype)
实例要访问构造函数:
function Person() {}
Person.prototype.age = 12;
var person = new Person();
console.log(person.__proto__.constructor === Person); // true因为,没有 实例 直接访问 构造函数 的属性和方法, 因此需要像上文所说的需要先通过 实例 的 __proto__ 访问 原型, 然后通过 原型 的 constructor 属性访问 构造函数.
在读取一个实例的属性的过程中, 如果在该实例中没有找到, 那么就会循着 __proto__ 指定的原型上去找, 如果仍找不到,则尝试寻找原型的原型:
function Person() {}
Person.prototype.age = 12;
var person = new Person();
console.log(Reflect.ownKeys(person));
console.log(person.age);原型链
原型也可以通过 __proto__ 访问原型的原型, 例如:
function Person() {}
Person.prototype.age = 12;
function People() {}
People.prototype = new Person();
var p = new People();
console.log(p instanceof Object, p instanceof Person, p instanceof People); // true true true
console.log(p.age); // 12上述代码, 当访问 p 中一个非自有属性时, 就会通过 __proto__ 作为桥梁连接起一系列原型、原型的原型、原型的原型的原型直到 Object 构造函数为止, 这种搜索过程形成的链状关系就是原型链.
详细例子:
function Person() {}
Person.prototype.age = 12;
function People() {}
People.prototype = new Person();
var p = new People();
console.log(p.__proto__); // Person {}
console.log(p.__proto__.__proto__); // Person {age: 12}
console.log(p.__proto__.__proto__.__proto__); // {}
console.log(p.__proto__.__proto__.__proto__.__proto__); // null构造函数 原型对象 实例 之间的关系
function F() {}
var f = new F();
console.log(F.prototype.constructor === F); // true
console.log(F.**__proto__** === Function.prototype); // true
console.log(Function.prototype.__proto__ === Object.prototype); // true
console.log(Object.prototype.__proto__ === null); // true
console.log(f.__proto__ === F.prototype); // true
console.log(F.prototype.__proto__ === Object.prototype); // trueJS 创建对象的几种方式
工厂模式
- 缺点:对象无法识别,因为所有的实例都指向一个原型
function createPerson(name) {
var o = new Object()
o.name = name
o.getName = function() {
console.log(this.name)
}
return o
}
var person = createPerson('even')构造函数模式
- 优点:实例可以识别为一个特定的类型
- 缺点:每次创建实例时,每个方法都要创建一遍
function Person(name) {
this.name = name
this.getName = function () {
console.log(this.name)
}
}
var person = new Person('even)原型模式
- 优点:方法不会重复创建
- 缺点:
- 所有的属性和方法都共享
- 不能初始化参数
function Person() {
}
Person.prototype.name = 'even'
Person.prototype.getName = function () {
console.log(this.name)
}
var person = new Person()原型模式优化 1
- 优点:封装性好一些
- 重写了原型,丢失了 constructor 属性
function Person() {
}
Person.prototype ={
name: 'even',
getName: function () {
console.log(this.name)
}
}
var person = new Person()原型模式优化 2
- 优点:实例可以通过 constructor 属性找到所属构造函数
- 缺点:原型模式的缺点还是有
function Person() {
}
Person.prototype ={
constructor: Person,
name: 'even',
getName: function () {
console.log(this.name)
}
}
var person = new Person()组合模式
构造模式和原型模式的联合
- 优点:该共享的共享,该私有的私有,使用最广泛
- 缺点:有的人就是希望全部写在一起,即更好的封装性
function Person(name) {
this.name = name
}
Person.prototype = {
constructor: Person,
getName: function () {
console.log(this.name)
}
};
var person = new Person()动态原型模式
function Person(name) {
this.name = name
if (typeof this.getName != 'function') {
Person.prototype.getName = function () {
console.log(this.name)
}
}
}
var person = new Person()寄生构造函数模式
function Person (name) {
var o = new Object()
o.name = name
o.getName = function () {
console.log(this.name)
}
return o
}
var person = new Person('even')
console.log(person instanceof Person) // false
console.log(person instanceof Object) // true稳妥构造函数模式
所谓稳妥对象,指的是没有公共属性,而且其方法也不引用 this 的对象。
与寄生构造函数模式有两点不同:
- 新创建的实例方法不引用 this
- 不使用 new 操作符调用构造函数
稳妥对象最适合在一些安全的环境中。
稳妥构造函数模式也跟工厂模式一样,无法识别对象所属类型。
function person (name) {
var o = new Object()
o.sayName = function () {
console.log(name)
}
return o
}
var person = person('even')
person.sayName() // even
person.name = 'amom'
person.sayName() // even
console.log(person.name) // amomJS 中 SSE
SSE 即 Server-sent events,使用 server-send 事件,服务器可以在任何时刻向我们的 web 服务器推送数据和信息。
浏览器为我们提供了 web api:EventSource 来使用 SSE。
使用示例:
- 接收匿名消息事件
if (window.EventSource) {
var sse = new EventSource('sse.php')
var eventList = document.querySelector('ul')
sse.onmessage = function(e) {
var newElement = document.createElement("li");
newElement.textContent = "message: " + e.data;
eventList.appendChild(newElement);
}
}- 接收具名消息事件
if (window.EventSource) {
const url = '/api/v1/sse/'
const sse = new EventSource(url)
const events = ['notice', 'update']
events.map(event => {
sse.addEventListener(event, e => {
console.log(e)
}
})
}柯里化与偏应用
什么是柯里化
柯里化是把一个多参数函数转换为一个嵌套的一元函数的过程。
可以这样理解柯里化 :用闭包把参数保存起来,当参数的数量足够执行函数了,就开始执行函数,有没有毛病
简单柯里化例子
// 普通函数
const add = (x, y) => x + y
// 柯里化函数
const addCurried = x => y => x + y实现柯里化
function curry(fn, args) {
var length = fn.length;
args = args || [];
return function() {
var _args = args.slice(0),
arg, i;
for (i = 0; i < arguments.length; i++) {
arg = arguments[i];
_args.push(arg);
}
if (_args.length < length) {
return curry.call(this, fn, _args);
}
else {
return fn.apply(this, _args);
}
}
}
var fn = curry(function(a, b, c) {
console.log([a, b, c]);
});
fn("a", "b", "c") // ["a", "b", "c"]
fn("a", "b")("c") // ["a", "b", "c"]
fn("a")("b")("c") // ["a", "b", "c"]
fn("a")("b", "c") // ["a", "b", "c"]JS 中的排序
快排
- 取中间值递归排序
- 需要注意两点
- 数组长度小于等于一时需要返回
- 取 middleValue 时需要用 splice 更改数组
function quickSort(arr) {
const len = arr.length
if (len <= 1) return arr
const middleIndex = Math.floor(len/2)
const middleValue = arr.splice(middleIndex, 1)[0]
let leftArr = []
let rightArr = []
for (let i = 0; i < arr.length; i++) {
if (arr[i] <= middleValue) {
leftArr.push(arr[i])
} else {
rightArr.push(arr[i])
}
}
return quickSort(leftArr).concat([middleValue], quickSort(rightArr))
}
const arr = [ -10, 10, 1, 34, 5, 1 ]
console.log(quickSort(arr))冒泡排序
- 从第一个元素开始比较,比较相邻的两个元素,前面的元素大就交换位置
- 每次遍历结束都会找打一个最大值
- 如果排序还不正确,继续重复步骤
function bubbleSort(arr) {
for (let i = 0; i < arr.length - 1; i++) {
for (let j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j+1]) {
const temp = arr[j]
arr[j] = arr[j+1]
arr[j+1] = temp
}
}
}
return arr
}
const arr = [2, 5, 3, 1, 6]
console.log('---------------arr---------------', bubbleSort(arr))选择排序
- 取出排序的元素与后面的每一个元素进行排序
- 如果更小则交换元素位置
function selectSort(arr) {
for (let i = 0; i < arr.length; i++) {
let minIndex = i
for (let j = i + 1; j < arr.length; j++) {
if (arr[minIndex] > arr[j]) {
minIndex = j
}
}
if (minIndex != i) {
let temp = arr[i]
arr[i] = arr[minIndex]
arr[minIndex] = temp
}
}
return arr
}
const arr = [2, 5, 3, 1, 6]
console.log('---------------arr---------------', selectSort(arr))插入排序
- 从数组第2个元素开始抽取元素。
- 把它与左边第一个元素比较,如果左边第一个元素比它大,则继续与左边第二个元素比较下去,直到遇到不比它大的元素,然后插到这个元素的右边。
- 继续选取第3,4,….n个元素,重复步骤 2 ,选择适当的位置插入。
冒泡、选择都是把未排序的和未排序的进行比较换位 而插入排序的思想是把未排序的和已经排好序的进行比较换位
function insertSort(arr) {
for (let i = 0; i < arr.length; i++) {
for (let j = i + 1; j >= 0; j--) {
if (arr[j] < arr[j - 1]) {
let temp = arr[j]
arr[j] = arr[j - 1]
arr[j - 1] = temp
} else {
break
}
}
}
return arr
}
let arr = [ -1, 10, 10, 2 ]
console.log('---------------arr---------------', insertSort(arr))call、apply、bind ES6 实现
call
Function.prototype.myCall = function(context, ...args) {
context = Object(context) || window
context.fn = this
context.fn(...args)
delete context.fn
}apply
Function.prototype.myApply = function(context, arr) {
context = Object(context) || window
context.fn = this
let result
if (!arr) {
result = context.fn()
} else {
result = context.fn(...arr)
}
return result
delete context.fn
}bind
Function.prototype.myBind = function(context) {
var self = this
var args = Array.prototype.slice.call(arguments)
var fNOP = function () {}
var fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments)
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs))
}
fNOP.prototype = this.prototype
fBound.prototype = new fNOP()
return fBound
}Object.prototype.toString.call()
Object.prototype.toString.call() 会返回形如 [object xxxx] 的字符串
而各大对象上的 toString 上的方法被重写,如 null.toString() 会报错
这是想要调用 toString 返回正确的数据类型,只需要调用 Object 原始的 toString 方法就可以了 Object.prototype.toString.call()
// Boolean 类型,tag 为 "Boolean"
Object.prototype.toString.call(true); // => "[object Boolean]"
// Number 类型,tag 为 "Number"
Object.prototype.toString.call(1); // => "[object Boolean]"
// String 类型,tag 为 "String"
Object.prototype.toString.call(""); // => "[object String]"
// Array 类型,tag 为 "String"
Object.prototype.toString.call([]); // => "[object Array]"
// Arguments 类型,tag 为 "Arguments"
Object.prototype.toString.call((function() {
return arguments;
})()); // => "[object Arguments]"
// Function 类型, tag 为 "Function"
Object.prototype.toString.call(function(){}); // => "[object Function]"
// Error 类型(包含子类型),tag 为 "Error"
Object.prototype.toString.call(new Error()); // => "[object Error]"
// RegExp 类型,tag 为 "RegExp"
Object.prototype.toString.call(/\d+/); // => "[object RegExp]"
// Date 类型,tag 为 "Date"
Object.prototype.toString.call(new Date()); // => "[object Date]"
// 其他类型,tag 为 "Object"
Object.prototype.toString.call(new class {}); // => "[object Object]"关系操作符
当关系操作符的两个操作数都是字符串的时候,会逐个比较它们的字符编码
'23' < '3' // false
如果数字和非数字字符串比较时,非数字字符串不能转换为任何有意义的数值,只能转换为
NaN,而任何关系操作符在涉及比较NaN时都返回false'a' < 3// falseNaN < 3// falseNaN >= 3// false
相等操作符和不相等操作符
- 如果任一操作数是布尔值,则将其转换为数值再比较是否相等
- 如果一个操作数是字符串,另一个操作数是数值,则尝试将字符串转换为数值,再比较是否相等
- 如果一个操作数是对象,另一个不是,则调用对象的
valueOf()方法取得其原始值,再根据前面的规则比较 null和undefined相等null和undefined不能转换为其他类型的值再比较- 如何任一操作数是
NaN,则相等操作符返回false,不相等操作符返回true。即使两个操作符都是NaN,相等操作符也返回false - 如果两个操作数都是对象,则比较它们是不是同一个对象。如果两个操作数都指向同一个对象,则相等操作符返回
true
RegExp
正则表达式 let expression = /pattern/flags 中 flags:
- g:全局模式,表示查找字符串的全部内容,而不是找到第一个匹配的内容就结束
- i:不区分大小写,表示在查找匹配时忽略 pattern 和字符串的大小写
- m:多行模式,表示查找到一行文本末尾时会继续查找
- y:粘附模式,表示知查找从 lastIndex 开始及之后的字符串
- u:Unicode 模式,启用 Unicode 匹配
- s:dotAll 模式,表示元字符匹配任何ZI福(包括\n活\r)
原始值包装类型
为了方便操作 JavaScript 中的原始值,ECMAScript 提供 3 种特殊的引用类型:Boolean、Number、String。
每当使用某个原始值的方法和属性时,后台会创建一个相应原始包装类型的对象,从而暴露出操作原始值的方法。
这里也就是说,原始值是逻辑上不会有相应的方法,当调用原始值上的方法属性时,会经历三步:
- 创建相应原始值的的实例 String、Boolean 或者 Number
- 调用实例上的特定方法
- 销毁实例
需要注意的是,在原始值包装类型的实例上调用 typeof 会返回 object,所以有原始值包装的对象都会转换为布尔值 true!!
注意
let boolean = new Boolean(false)
let result = boolean && true
console.log(result) // truePromise.all
每次使用 Promise.all 都会不明确,做个记录
const getPromiseList = async(questionId, answerId) => {
return new Promise(resolve => {
// 异步操作
parseSetContent(questionId, answerId).then(res => {
resolve(res)
})
})
}
Promis.all(answerList.map(asnwer => getPromiseList(questionId, asnwer.id)))函数传递参数
**所有函数的参数都是按值传递的!**这意味着函数外的值会被复制到函数内部的参数中,就像从一个变量复制到另一个变量一样。
如果是原始值,那么就跟原始值变量的复制一样。
如果是引用值,那么就跟引用值变量的复制一样。
eg:
function setName(obj) {
obj.name = 'Eason'
}
let person = new Object()
setName(person)
console.log(person.name) // Eason在上个例子中,创建了一个 person 对象,然后将对象传给 setName() 方法,并被复制到参数 obj 中。在函数内部,obj 和 person 都指向同一个对象。结果就是,即使对象是按值传进函数的,obj 也会通过引用访问对象。当函数内部给 obj 设置了 name 属性时,函数外部的对象也会反映这个变化,因为 obj 指向的对象保存在全局作用域的堆内存上。
很多人可能因为这个例子错误的认为,当在局部作用域中修改对象而变化反映到全局时,就意味着是按引用传递的。但这是错误的!!看下面的例子:
function setName(obj) {
obj.name = 'Eason'
obj = new Object()
obj.name = 'HEHE'
}
let person = new Object()
setName(person)
console.log(person.name) // Eason从上面的例子可以看出,如果函数参数是按引用传递,那么 person 应该自动将指针改为指向 name 为 HEHE 的对象。可是,当我们再次访问 person.name 时,它的值是 Eason,这表明函数中参数的值改变后,原始的引用仍然没变。当 obj 在函数内部被重写时,它变成一个指向本地对象的指针,本地对象在函数执行结束时就被销毁了。
宏任务 MacroTask 和 微任务 MicroTask
- 微任务:Process.nextTick、Promise.then catch finally、MutationObserver